Data-Efficient Image Transformers (DeiT)
Data-Efficient Image Transformers (DeiT)
DeiT is a model architecture proposed by Facebook AI and Sorbonne University in 2021. It is based on the Vision Transformer (ViT) architecture, but with some key differences that allow it to be trained on smaller datasets.
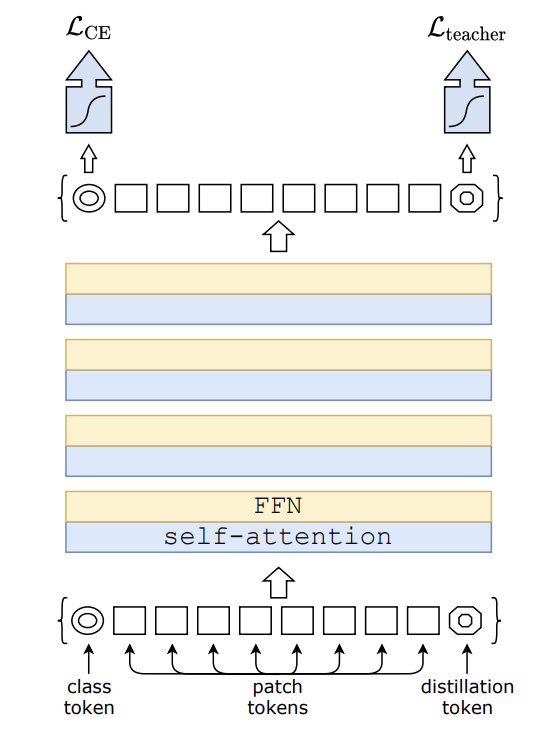
The main issue with the original ViT architecture is that it requires a large amount of training data to generalize well. DeiT addresses this issue by introducing a distillation token and a training strategy that allows the model to be trained on smaller datasets while still achieving good performance. The distillation token is an additional input token. It plays a similar role to the class token, but instead of representing the class label, it aims to reproduce the label estimated by the teacher during distillation.
The distillation token interacts with other embeddings through self-attention and is output by the network after the last layer. Its target objective is given by the distillation component of the loss. The authors found that this transformer-specific strategy outperforms vanilla distillation by a significant margin. This allows the DeiT model to learn from the output of the teacher model, effectively distilling its knowledge into the smaller DeiT model.
In addition to the distillation token, DeiT also introduces a new training strategy that involves using both hard and soft distillation, as well as a combination of classical distillation and the distillation token. Soft distillation minimizes the Kullback-Leibler (KL) divergence between the softmax of the teacher and the softmax of the student model. In other words, it aims to match the output probabilities of the teacher model with those of the student model. The temperature parameter is used to control the softness of the probability distribution. Soft distillation is contrasted with hard distillation, which takes the hard decision of the teacher as a true label. In hard-label distillation, the hard decision of the teacher is taken as a true label. In other words, the output of the teacher model is treated as a one-hot vector, where the maximum value corresponds to the predicted class. This is in contrast to soft distillation, which aims to match the output probabilities of the teacher model with those of the student model.