High-resolution 3T to 7T MRI Synthesis with a Hybrid CNN-Transformer Model
High-resolution 3T to 7T MRI Synthesis with a Hybrid CNN-Transformer Model
This paper proposes a novel approach to synthesizing high-resolution 7T apparent diffusion coefficient (ADC) maps from multi-modal 3T MRI using a hybrid CNN-transformer model. The proposed model is designed to improve the diagnostic capabilities of existing 3T scanners by enabling the generation of high-quality synthetic 7T ADC maps.
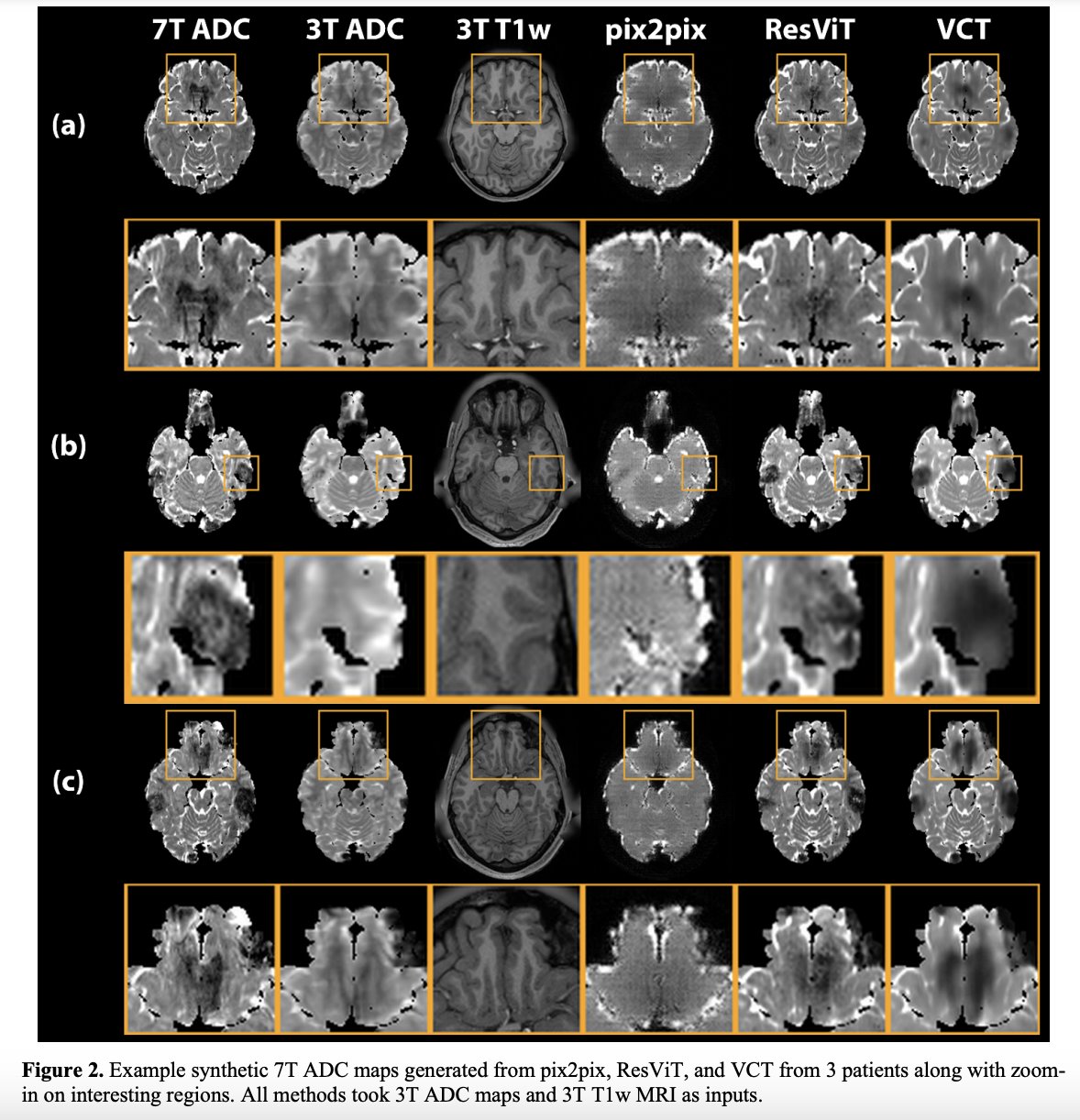
3T MRI is a widely used imaging technique that provides high-resolution images of the human body. However, 7T MRI offers even higher resolution images, which can be particularly useful in medical imaging applications. The challenge is that 7T MRI is not widely available, and it can be expensive and time-consuming to acquire.
The Vision CNN-Transformer (VCT) Model
The proposed model, called the Vision CNN-Transformer (VCT) model, is designed to learn localized and abstract features from both T1-weighted (T1w) and ADC map axial slices input as separate channels. The model then uses this learned information to generate high-quality synthetic 7T ADC maps.
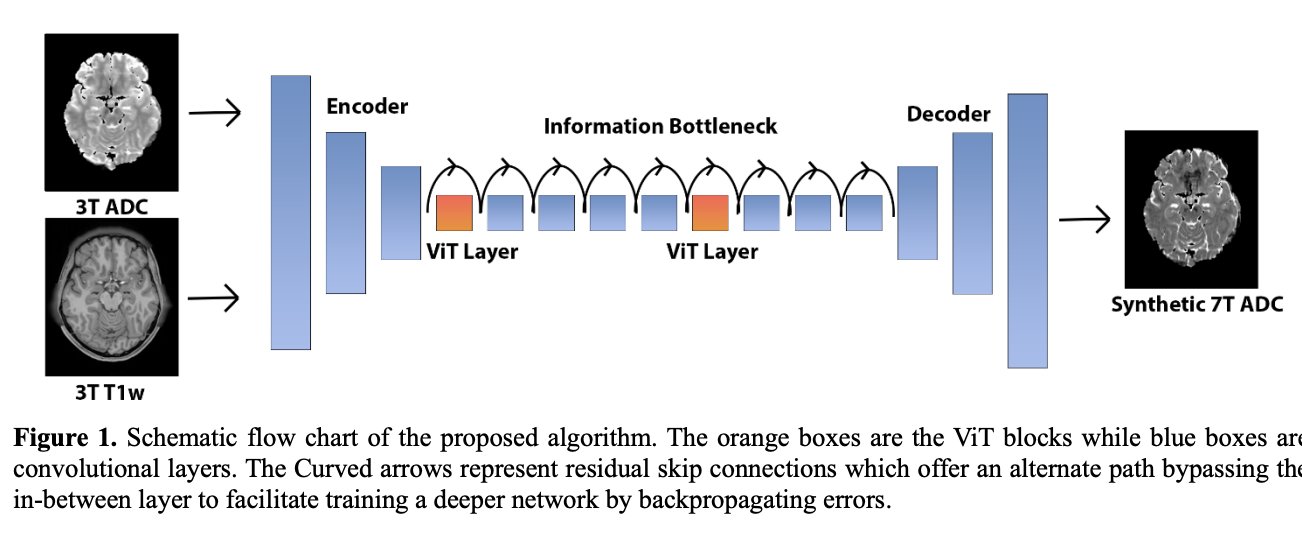
The model is composed of three main components: an encoder, an information bottleneck, and a decoder.
The encoder is responsible for learning localized features from the input data. It is composed of three convolutional blocks, with the first block having a large kernel size of 7x7 to capture broader image context. The following blocks are of kernel size 3x3 with a stride of 2, which further learn more abstract features and reduce the dimensionality by a factor of 4, easing the computational burden of the ViT blocks in the information bottleneck.
The information bottleneck is designed to encode abstract, long-distance features using both convolutional layers and more powerful ViT blocks to boost performance and more accurately capture global context. It has 9 layers connected with residual skip connections and does not change the dimensions of the feature maps. Two of these layers are transformer-based to allow for global context. The transformer layers share weights to reduce computational complexity.
The decoder is responsible for generating the high-resolution 7T ADC maps from the encoded features. It is similarly comprised of three blocks. The first two are transposed convolutional blocks with a kernel size of 3x3, which restores the dimensionality back to the original input spatial dimensions. Finally, a 7x7 convolutional layer captures fine detail over a relatively large area.
The model takes as input both 3T ADC map axial slices and 3T T1-weighted (T1w) MRI, which are input as separate channels. The encoder and decoder learn localized features and are connected by the information bottleneck, which encourages learning more abstract features. The information bottleneck has residual skip connections, which offer an alternate path bypassing the in-between layer to facilitate training a deeper network by backpropagating errors.